
Connect with us
Corporate Video

A Guide to Popular Generative AI Models and Their Applications

When it comes to naming the most exciting and promising fields of artificial intelligence, Generative AI certainly tops the list. So what is generative AI exactly? It refers to the ability of AI systems to create novel and original content or data that is not based on existing inputs, but rather on learned patterns and rules. One can utilize generative AI to produce diverse and realistic outputs, such as text, images, video, audio, and more. As a result, the applications and benefits of generative AI are many. Here are a few of them at a glance.
- Enhancing creativity and innovation by generating novel and original ideas.
- Improving productivity and efficiency by automating tasks that require human input.
- Solving complex problems and challenges by exploring multiple scenarios and outcomes.
- Entertaining and educating people by creating engaging and interactive content.
In this blog, we will discuss what are the popular generative AI models that have gained prominence in recent times. These models use different techniques and architectures to generate different types of content, including natural language, computer code, visual art, and music, among others. We will also look at some of the use cases and limitations of these models, as well as their implications for the future of AI.
Generative AI Models Explained
Generative artificial intelligence (AI) models are a fusion of various AI algorithms designed for the representation and processing of data. These models utilize various natural language processing techniques to transform raw characters, including letters, punctuation, and words, into meaningful sentences, parts of speech, entities, and actions. The resulting output is then encoded into vectors using a variety of encoding methods. Likewise, when it comes to images, they are converted into different visual elements, also represented as vectors.
(Note: It's crucial to acknowledge that while these techniques are powerful, they can inadvertently encode biases, racism, misinformation, and exaggeration that might be present in the training data. Developers must exercise caution and be aware of these limitations as they handle and represent data.)
Once developers have settled on a data representation approach, they employ specific neural networks to generate fresh content in response to queries or prompts. This process involves the utilization of techniques like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), which are particularly suited for creating realistic human faces, generating synthetic data for AI training, or producing simulations of specific individuals.
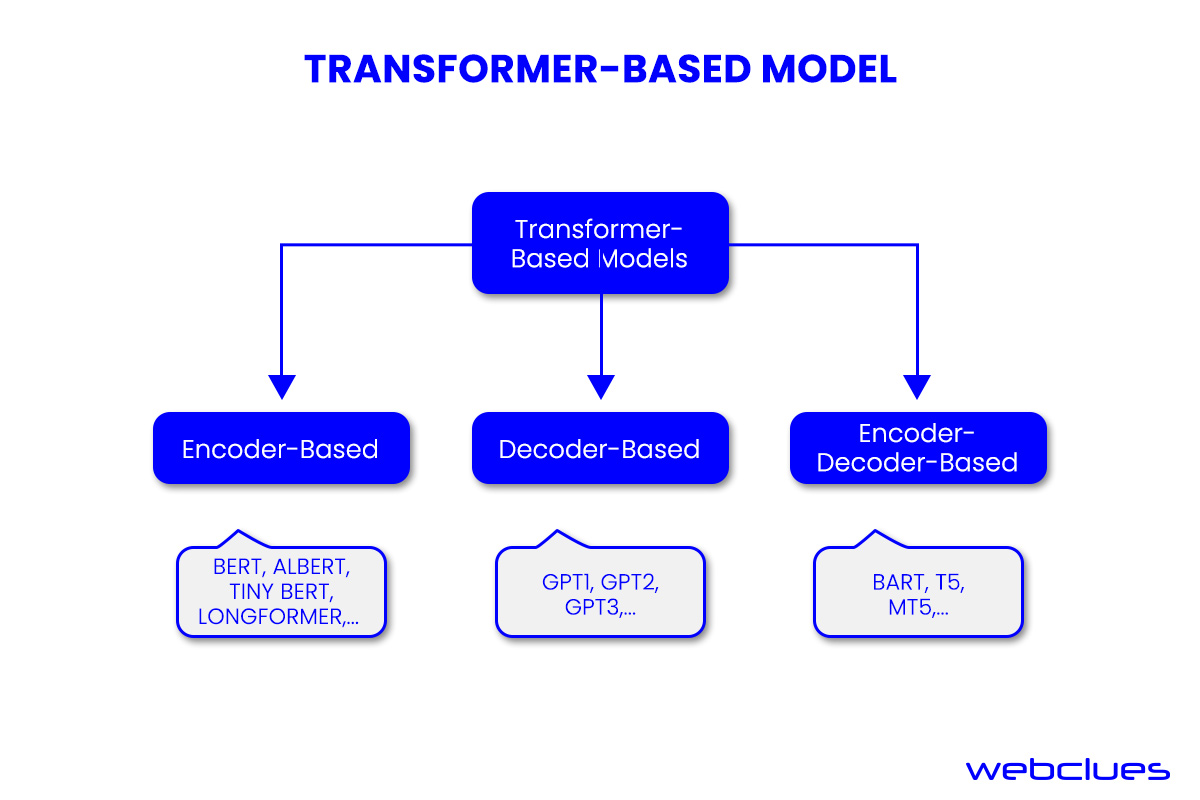
Then there are transformer-based models, such as Google's Bidirectional Encoder Representations from Transformers (BERT), OpenAI's Chat GPT, and Google AlphaFold, which not only excel in encoding language, images, and proteins but also exhibit remarkable prowess in generating entirely new content.
Types of Generative AI Models
There are several types of generative AI models that are most prominently utilized to develop different applications. Let’s explore them one by one.
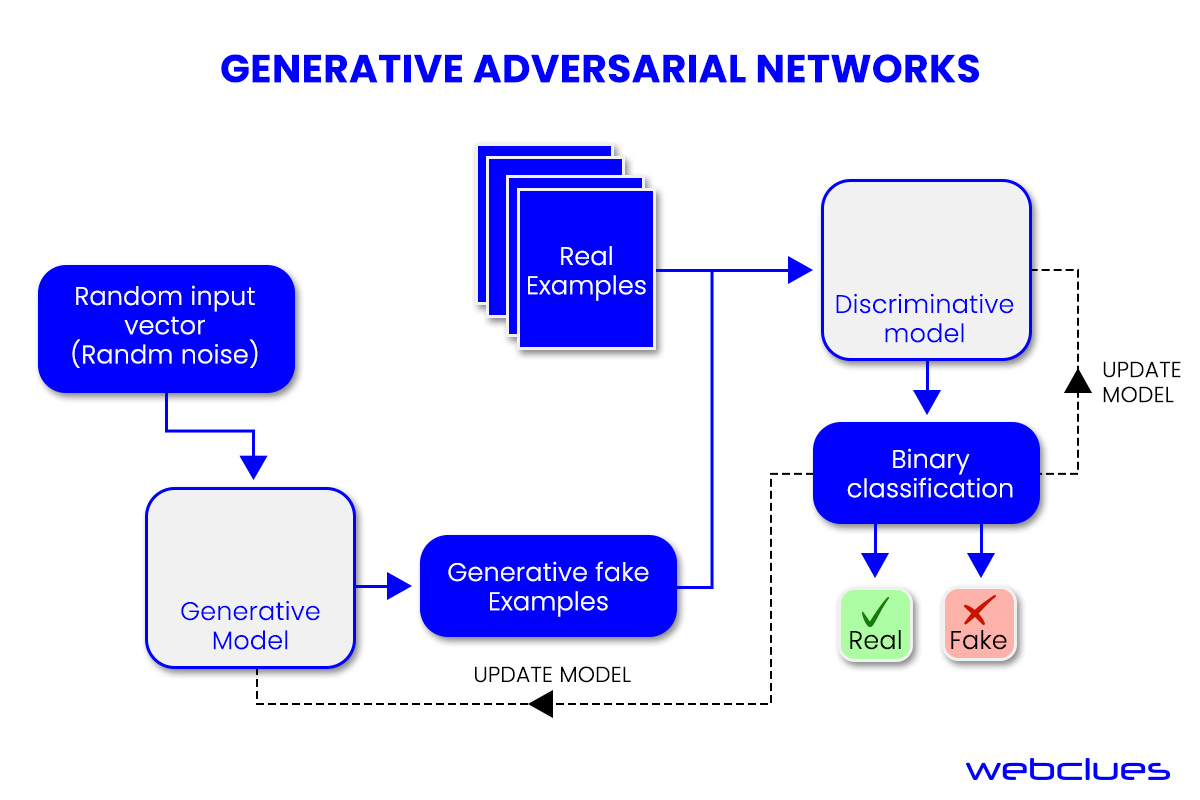
Generative Adversarial Networks (GANs)
GANs are a type of machine learning model that uses deep learning methods to create new data based on existing data. GANs have two sub-models, called the generator and the discriminator, that compete with each other in a game-like scenario to produce more realistic examples of the data they are trying to mimic.
In GANs, there's a dynamic interplay between the generator and the discriminator. The generator's role is to produce novel instances, while the discriminator's task is to distinguish between the generated ones and real data. Through this repeated process, the generator learns to make examples that are more and more similar to real data, making GANs a useful tool for creating new content, such as images, music, and text. This synthesis of imagery and text enables these technologies to generate diverse visual and multimedia creations.
Popular Generative AI Tools Based on GANs
- WaveGAN:
WaveGAN is primarily utilized to generate new audio data based on patterns learned from existing audio data. Its approach is similar to that of the popular DCGAN for generating images, however, it uses one-dimensional filters and upsampling to create raw waveform audio instead of image-like spectrograms. WaveGAN can learn to synthesize audio in many different sound domains, such as speech, music, and sound effects. It is implemented using TensorFlow and can be trained on any folder containing audio files.
- CycleGAN:
CycleGAN can translate images from one domain to another without having paired examples. For instance, it can turn photos of horses into zebras, or paintings into photos, using only unpaired collections of images from both domains. It uses two sub-models, a generator and a discriminator, for each domain. The generator tries to create fake images that look like they belong to the other domain while the discriminator tries to distinguish between real and fake images. To ensure that the translation is consistent and preserves the content of the original image, CycleGAN also uses a cycle consistency loss that measures the difference between the original image and the reconstructed image after a round trip through both generators. It can be used for various top generative AI applications such as style transfer, image enhancement, object transformation, and more.
Transformer-Based Model
Transformers are a type of neural network designed to excel in understanding context and meaning by scrutinizing relationships within sequential data. They employ cognitive attention to assess the significance of various input data components. Essentially, transformers are geared towards comprehending both language and images and subsequently generating text or images, with their learning foundation being vast datasets. For instance, generative Pre-Trained (GPT) language models harness internet-derived information to produce content for websites, press releases, and whitepapers.
Transformers were first created by a Google Brain team in 2017 to improve language translation. They have a special ability to process data in different orders than they appear, perform parallel processing, and scale up to build large models with unlabeled data.
Transformers can do many tasks that involve text summarization, chatbots, recommendation engines, language translation, knowledge bases, hyper-personalization through preference models, sentiment analysis, and named entity recognition for identifying people, places, and objects. They can also perform speech recognition, like OpenAI’s Whisper, object detection in videos and images, image captioning, text classification, and dialogue generation.
However, transformers are not perfect. They can be costly to train and need a lot of data. The models they produce can be very large, which can make it hard to find errors or biases. Also, their complexity may make it difficult to explain how they work and why they make certain decisions.
Popular Generative AI Tools Based on Transformer Model
- GPT-4:
GPT-4 is a new and advanced system created by OpenAI that can produce text that is similar to human speech and reasoning. It can also process images and generate text based on them. GPT-4 is trained on a huge amount of data from the internet, such as books, websites, and social media. GPT-4 is more reliable, creative, and able to handle more complex tasks than its predecessor, GPT-3.5 or ChatGPT.
You can use these powerful models to create and improve various generative AI applications and tools that involve language and text. For example, you can build your own chatbots, enhance your CRM platforms, answer questions on a specific topic, or do other tasks like summarizing and generating text.
- Google BARD:
Google BARD is a new and experimental AI chatbot that can generate text based on your questions or prompts. It uses a large language model called LaMDA, which can understand and produce natural and coherent language. BARD can help you with various tasks, such as summarizing texts, writing stories, creating jokes, and more. You can interact with BARD through text, voice, or images. It is integrated with some of the Google services you already use, such as Gmail and Docs.
- LLaMA:
LLaMA is a new and powerful AI system that can create and understand natural language using large language models (LLMs). LLaMA was developed by Meta AI, a company that specializes in building AI solutions for various domains. LLaMA has four different versions, each with a different number of parameters: 7, 13, 33, and 65 billion. Parameters are the values that determine how the AI model learns from data and generates outputs. The more parameters a model has, the more complex and capable it is. LLaMA can perform various tasks, such as answering questions, summarizing texts, generating stories, and more.
- Whisper:
Whisper can recognize and generate speech in English and other languages. It was created by OpenAI and uses a large and diverse dataset of speech data collected from the web, which helps it to be more accurate and robust to different accents, noises, and terms. Whisper can do various tasks, such as transcribing speech, identifying languages, giving timestamps, and translating speech to English.
- BioGPT:
BioGPT was developed by Microsoft Research and is trained on a huge amount of biomedical literature from the web, which helps it to be more accurate and robust to different biomedical terms and concepts. It can answer questions, summarize texts, generate stories, and more.
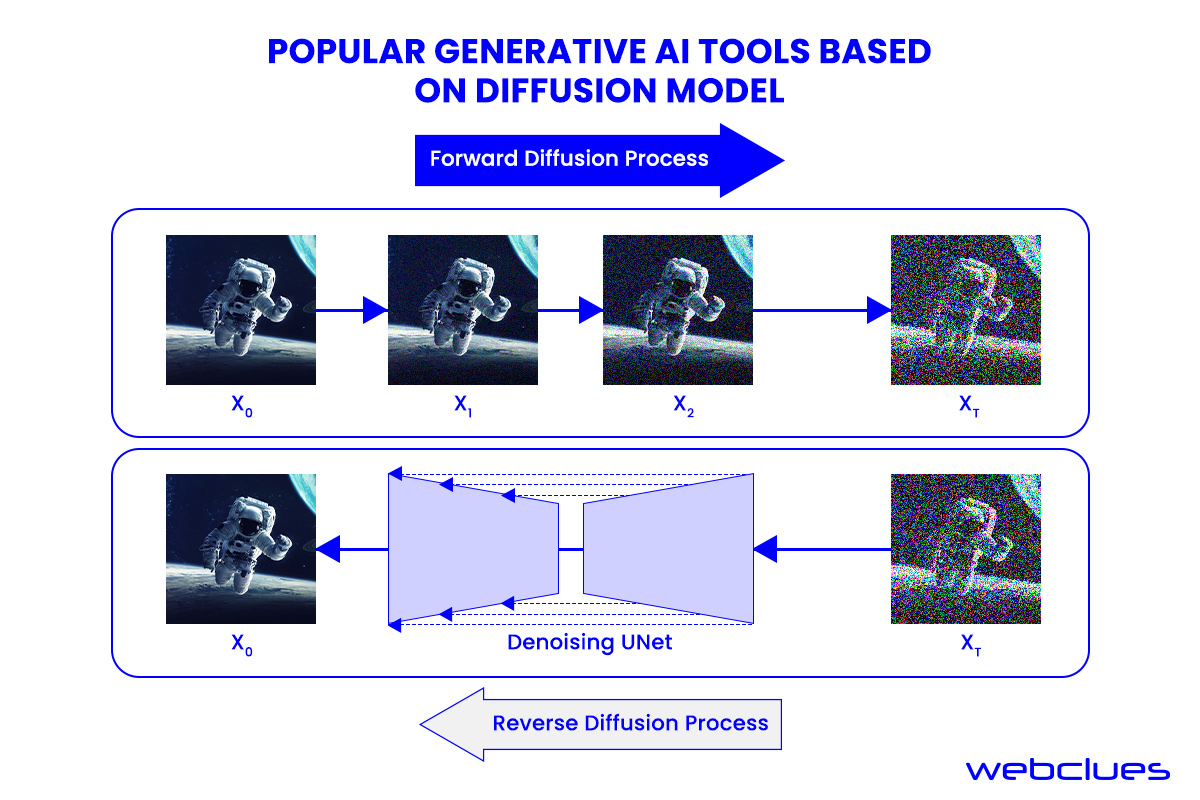
Diffusion Model
Diffusion models, also known as denoising diffusion probabilistic models (DDPMs), are vital in artificial intelligence and machine learning. They employ a two-step training process involving forward diffusion, where noise is added to data, and reverse diffusion, which reconstructs data by removing noise. This process can generate new data from random noise.
These models are recognized as foundation models due to their scalability, high-quality output, flexibility, and wide-ranging applicability. However, reverse sampling can be time-consuming.
Originating in 2015 at Stanford, diffusion models aim to model and reverse entropy and noise. Terms like "Stable Diffusion" are often used interchangeably with diffusion, highlighting the technique's importance.
Diffusion models are the go-to for image generation, underpinning popular services like DALL-E 2, Stable Diffusion, Midjourney, and Imagen. They're also essential for voice, video, and 3D content generation, as well as data imputation. In various applications, diffusion models are combined with a Language-Image Pre-training model for tasks like text-to-image and text-to-video generation.
Future improvements may focus on refining negative prompting, generating specific artistic styles, and improving celebrity image generation.
Popular Generative AI Tools Based on Diffusion Model
- Stable Diffusion:
Stable Diffusion is a type of artificial intelligence model that can generate realistic images from text descriptions. It uses a technique called latent diffusion, which gradually transforms random noise into an image that matches the text input. Stable Diffusion is an open-source project, which means anyone can access its code and model weights. It can run on most computers with a decent graphics card. Stable Diffusion can create images of anything you can imagine, such as animals, landscapes, people, and more. It can also modify existing images by inpainting, outpainting, or image-to-image translation.
- DALL-E 2:
DALL-E 2 can create realistic images and art from a description in natural language. It is an improved version of DALL-E, which was introduced by OpenAI in January 2021. DALL-E 2 can generate images with 4x greater resolution and more accuracy than DALL-E. It can also modify existing images by inpainting, outpainting, or image-to-image translation. can create images of anything you can imagine, such as animals, landscapes, people, and more.
- MidJourney:
MidJourney is an independent research lab that creates and hosts a text-to-image AI service. Along with generating realistic images from natural language descriptions, it also has a describe function that can generate text prompts from existing images.
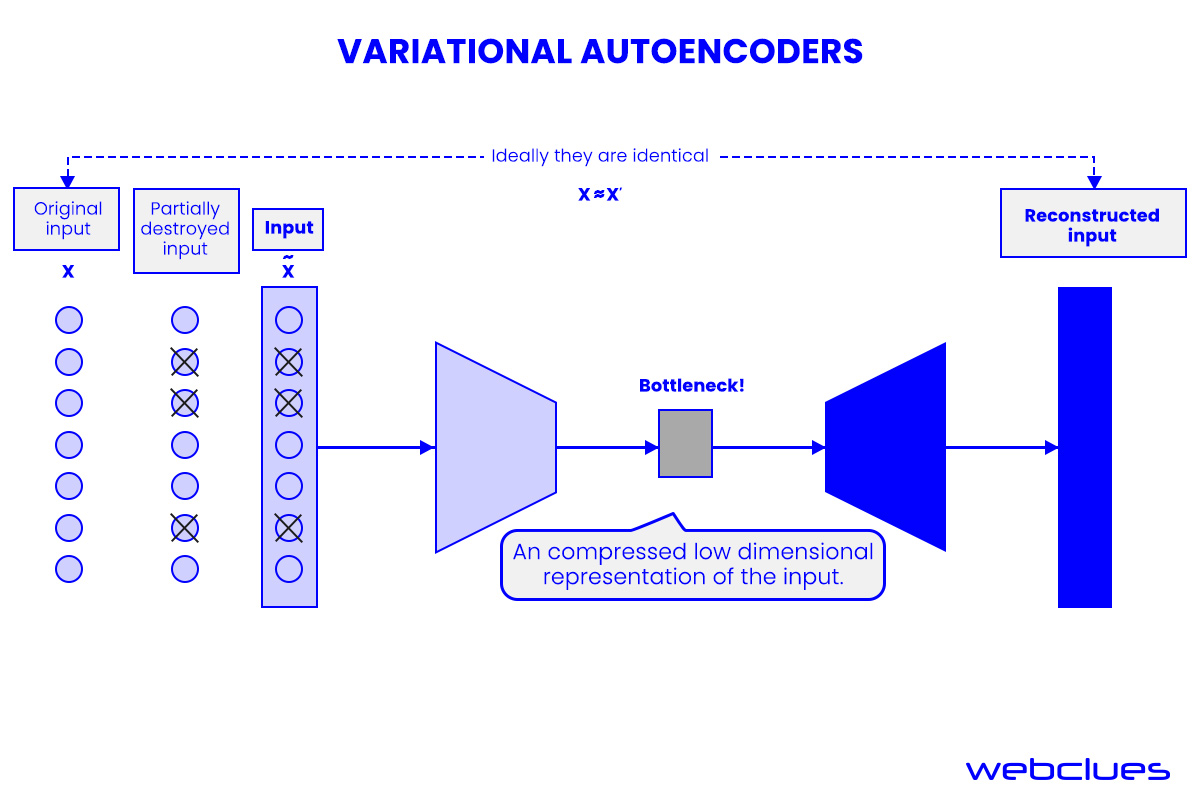
Variational Autoencoders (VAEs)
Variational AutoEncoders (VAEs) are a potent generative model akin to GANs. They utilize two neural networks, encoders, and decoders, to collaboratively create efficient generative models. Encoders learn efficient data representations, while decoders regenerate the original dataset.
VAEs are highly valuable for constructing complex generative models, especially with extensive datasets. They enable the generation of novel images by sampling from the latent distribution, resulting in unique and original content.
Introduced in 2014, VAEs aim to enhance data encoding efficiency using neural networks. VAEs excel at efficient information representation. They comprise an encoder to compress data and a decoder to restore it. VAEs can generate new instances, rectify noisy data, identify anomalies, and complete missing information.
However, VAEs tend to produce blurry or low-quality images. The latent space, capturing data structure in a lower-dimensional format, can be complex. Future VAE iterations aim to improve data generation quality, enhance training speed, and explore sequential data applications.
Wrapping It Up
Generative AI models have ushered in a new era of creativity and automation, enabling the generation of diverse content, from text to images and beyond. All the different types of models have their unique strengths and applications. As they continue to evolve, their impact on various domains and industries is poised to be transformative. However, it's crucial to remain mindful of their limitations, such as potential biases and complex model structures, as we explore the potential of generative AI in shaping the future of artificial intelligence.
At Webclues Infotech, we recognize the immense potential of generative AI and the value it holds for businesses and organizations seeking innovation and automation. Our Generative AI app development services are designed to empower you with cutting-edge solutions that leverage the full potential of these AI models.
Whether you're in need of AI-driven content generation, image manipulation, or data imputation, hire generative AI developers with us. Our expert team stands ready to tailor generative AI solutions to your specific requirements. From personalized chatbots to automated content creation, the possibilities are limited only by your imagination.
Post Author

Nikhil Patel
Nikhil Patel, a visionary Director at WebClues Infotech, specializes in leveraging emerging tech, particularly Generative AI, to improve corporate communications. Through his insightful blog posts, he empowers businesses to succeed digitally.


Build Your Agile Team
Hire Skilled Developer From Us
Learn about which Generative AI model is best suited for your upcoming project.
Our team of Generative AI experts at Webclues can help you choose the most efficient model for your next project and ensure that it meets your desired goals.
Book Free ConsultationOur Recent Blogs
Sharing knowledge helps us grow, stay motivated and stay on-track with frontier technological and design concepts. Developers and business innovators, customers and employees - our events are all about you.