
Connect with us
Corporate Video

The Technology Behind Generative AI: How Generative AI Works?

The current digital landscape is evolving rapidly, requiring businesses to seek innovative ways to stand out and engage with their customers. One technology that has piqued substantial interest among these businesses is Generative Artificial Intelligence (AI). This is because of its extraordinary ability to create new and original content in a blink of an eye – be it compelling text, music that mimics Mozart’s style, images that resemble masterpieces by accomplished artists, or even entire virtual environments. But what happens behind the curtain?

In this article, we aim to decode how generative AI works, the inner mechanics, and various types of generative AI models. We will also shed some light on how businesses can harness the potential of generative AI for organizational growth and customer satisfaction.
What is Generative AI?
Generative AI is a particular type of artificial intelligence that creates unique and compelling content in the form of text, image, video, or audio by learning from existing data patterns. It is different from traditional AI systems in a way that it does not rely on pre-defined rules or structures and generates new and original outputs. It produces coherent and aesthetically pleasing content of various types by leveraging advanced deep-learning models that mimic human creativity.
We will not go further deeper into the concept, benefits, or applications of generative AI. If you want to know everything about generative AI in detail, we have covered it in a distinct all-inclusive article. As for now, let’s bring back the focus on our main question and dive deep into the workings of generative AI.
How Does Generative AI Work?
At the heart of generative AI lies machine learning, which in turn is based on neural network architecture. Neural networks consist of interconnected layers of artificial neurons and are designed to mimic the working of the human brain. These networks can be trained to perform a diverse range of tasks, which also include generative tasks.
Generative AI models, with these neural networks at their base, are trained on large datasets, which can include images, text, audio, or videos. These models analyze the intricate relationship within the data and sample a probability distribution they have learned and generate new content that is similar to the input examples. The probability of generating accurate output is maximized by continuously adjusting the parameters of these models. This ability to learn and mimic patterns provides generative AI with its creative edge.
To put it in simpler words, consider the following example. Consider a generative AI model trained on a dataset of handwritten digits. New and realistic-looking handwritten digits can be created using this model by sampling from the learned distribution and refining the output through the process of “inference”.

Generative AI Models
There are several prominent types of generative AI models, each with its pros and cons. We will discuss some of the most widely recognized ones below.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks or GANs as a type of neural network architecture have revolutionized generative AI. It consists of two primary components: the generator and the discriminator.
The generator creates new and original output, such as images, based on random input or a given condition. It trains on an existing dataset and learns to generate output that resembles real examples. Initially, the output may be random pixels, but as the training progresses, the generator produces a more realistic and coherent output.
The discriminator, on the other hand, acts as a critic. Taking input from both the generator and real examples from the training dataset, it attempts to differentiate between the real and generated content. It progressively learns to classify whether an input is real or fake.
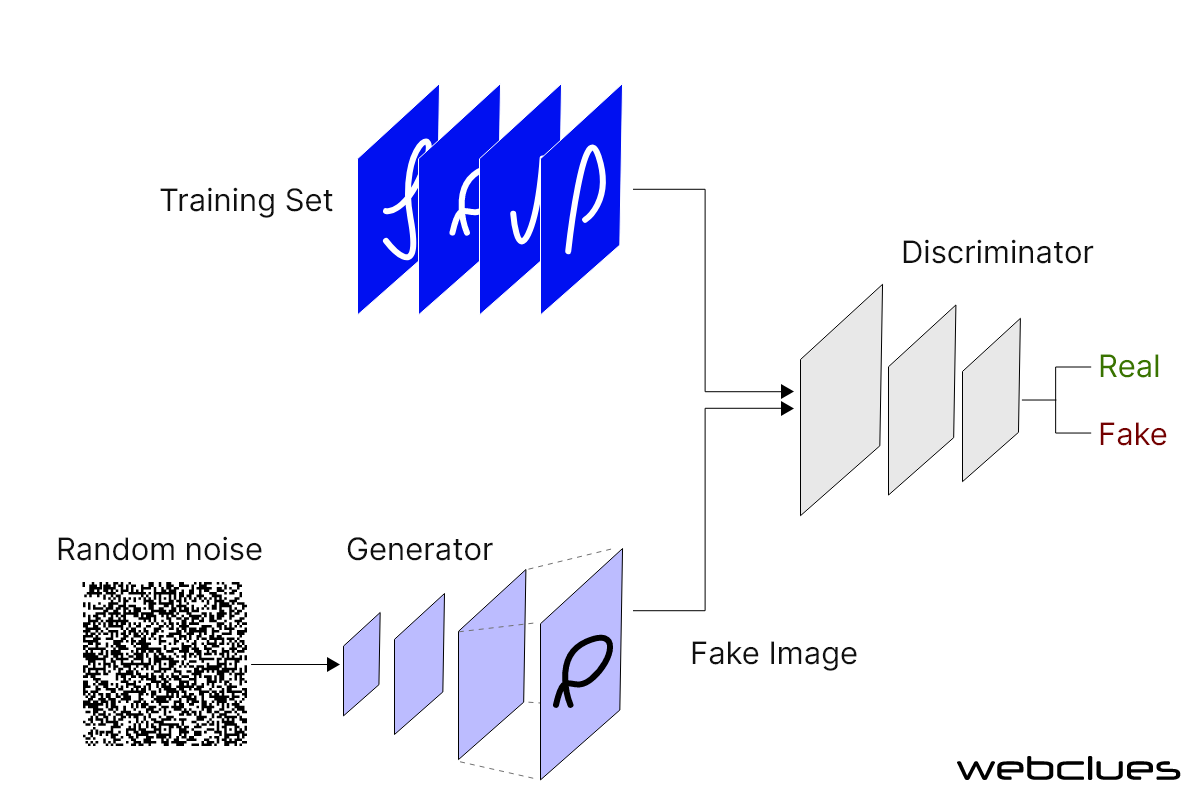
The training of GANs as a whole involves a back-and-forth interplay between the generator and the discriminator. With consistent progress in training, the generator learns to produce outputs that are increasingly more difficult for the discriminator to classify, while the discriminator becomes more adept at distinguishing between real and generated examples. Essentially, both components improve their performance as the training progresses.
This iterative process carries on until the generator can consistently fool the discriminator by generating outputs that are indistinguishable from the real example. This way, both the components work as each other’s adversaries and hence the use of the term “adversarial” in the name. Thus, GANs generate novel and high-quality content by learning to capture the intrinsic patterns and details in the training data.
The Training Process of GANs
GANs training process involves the following steps:
- Initialization: Initializing the generator and discriminator with random weights.
- Training loop: The generator generates fake data, discriminator classifies real and fake data by outputting a probability score between 0 and 1.
- Backpropagation: The error signal from the discriminator is backpropagated to update generator weights.
- Sampling: The generator, once trained, produces new data by sampling from learned distribution.
GANs Benefits
- Generates realistic, images, speech, and videos
- Produces high-quality and diverse samples by learning complex and multi-modal distributions
Challenges
- Training difficulties
- Prone to mode collapse
Potential GAN Applications
- Image/video generation and manipulation, including deep fakes
- Image-to-image translation and style transfer
- Data augmentation and synthesis to improve the performance of supervised learning models
- Image captioning and text-to-image synthesis
- 3D generation and design
- Audio synthesis and voice conversion
- Game development and design
- Creative applications
- Security & privacy: fake data creation and deep fake detection
- Scientific research & simulation
One of the real-life examples based on GANs is NVIDIA’s StyleGAN. It is utilized in gaming, fashion, and art for generating realistic human faces. It exemplifies GAN’s potential to bridge real and synthetic imagery by enhancing gaming experiences, creating virtual models, and fueling artistic exploration.
Transformer-Based Models
Transformer-based models are another prominent type of neural network architecture with a self-attention mechanism at its base. They are particularly well-suited to perform tasks that involve sequential data. This includes tasks like natural language processing (NLP) and machine translation.
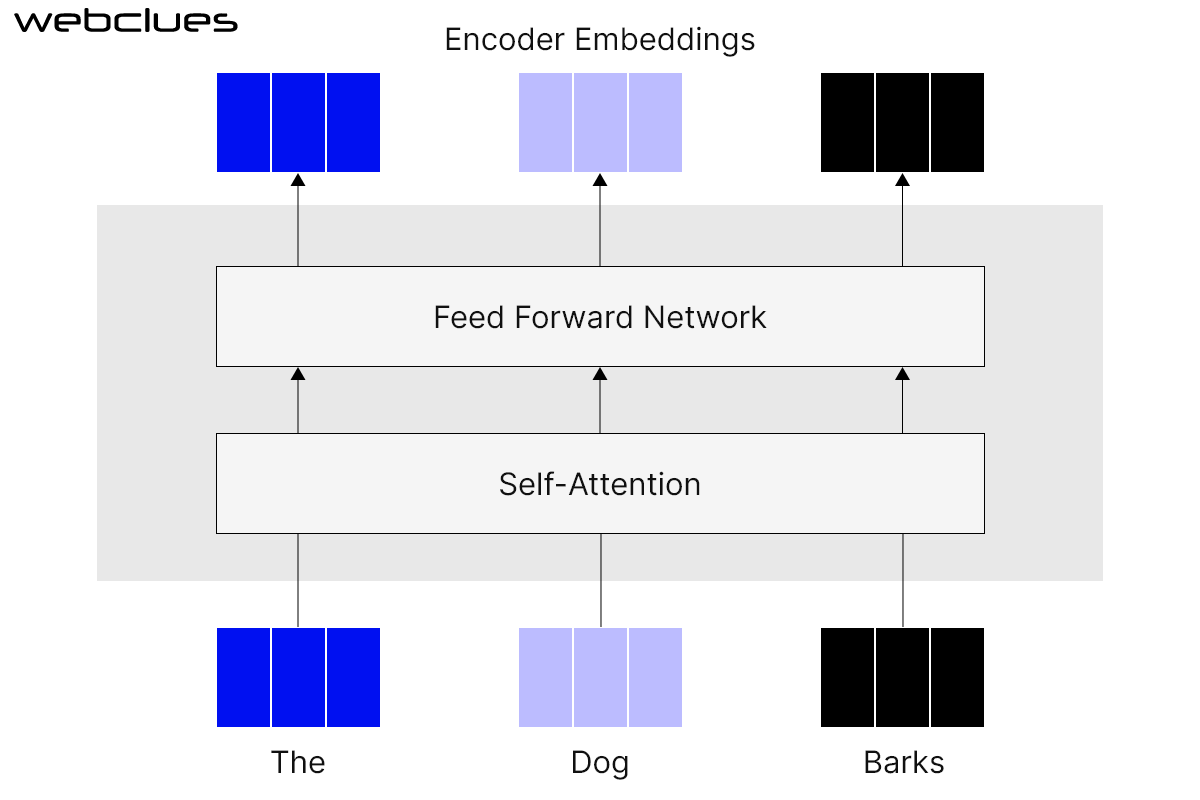
Transformer-based models learn the relationship between different parts of a sequence by using the attention mechanism. This enables them to capture long-range dependencies, essential for many NLP tasks. For instance, on receiving an input the model assigns weights to various parts of the input sequence in parallel. Once it identifies their relationship, it generates output particular to the specific input.
Training Process of Transformer-Based Models
The training process of transformer-based models involves the following steps:
- Tokenization: Input text is converted into tokens or padded sequences of fixed length like BPE or WordPiece.
- Embedding: Subword tokens are embedded into dense vector representations
- Encoder-Decoder Architecture: The model comprises an encoder and a decoder, with each layer consisting of a self-attention mechanism and feed-forward neural networks.
- Self-Attention: The mechanism enables the model to capture long-range dependencies by weighing the importance of different words in a sentence.
- Autoregressive Generation: Based on the processed input the decoder produces the output sequence.
Benefits of Transformer-Based Models:
- Ability to capture long-range dependencies in sequential data
- Pre-training captures rich language representations by pre-training on large-scale corpora using unsupervised learning.
- Produces impressive results on a variety of NLP tasks, including machine translation, question-answering, and text summarization.
Challenges of Transformer-Based Models:
- Transformers require relatively higher computational power and a significant amount of resources which leads to slower training and inference times.
- Requires a vast amount of training data for proper generalization and optimal performance.
- Specialized techniques and careful hyperparameter training are required to fine-tune pre-trained transformer models for specific tasks
Potential Application of Transformer-Based Models
- Machine translation
- Natural Language Understanding
- Conversational AI
- Speech Recognition
- Image captioning
- Text generation, summarization, and question-answering
- Document Classification
Open AI’s GPT-3 is one of the largest language models based on transformers. It is capable of generating original text, translating languages, generating various forms of creative content, and answering your questions in an informative way.
Variational Autoencoders (VAEs)
Variational autoencoders or VAEs is a generative AI model well-known for its ability to offer variation in the data in a specific direction rather than just generating new content that resembles that training data.
VAEs are neural network architectures comprising an encoder and a decoder. The encoder compresses the input data into a lower-dimensional representation, called the “latent space”, while the decoder reconstructs it and generates a new output.
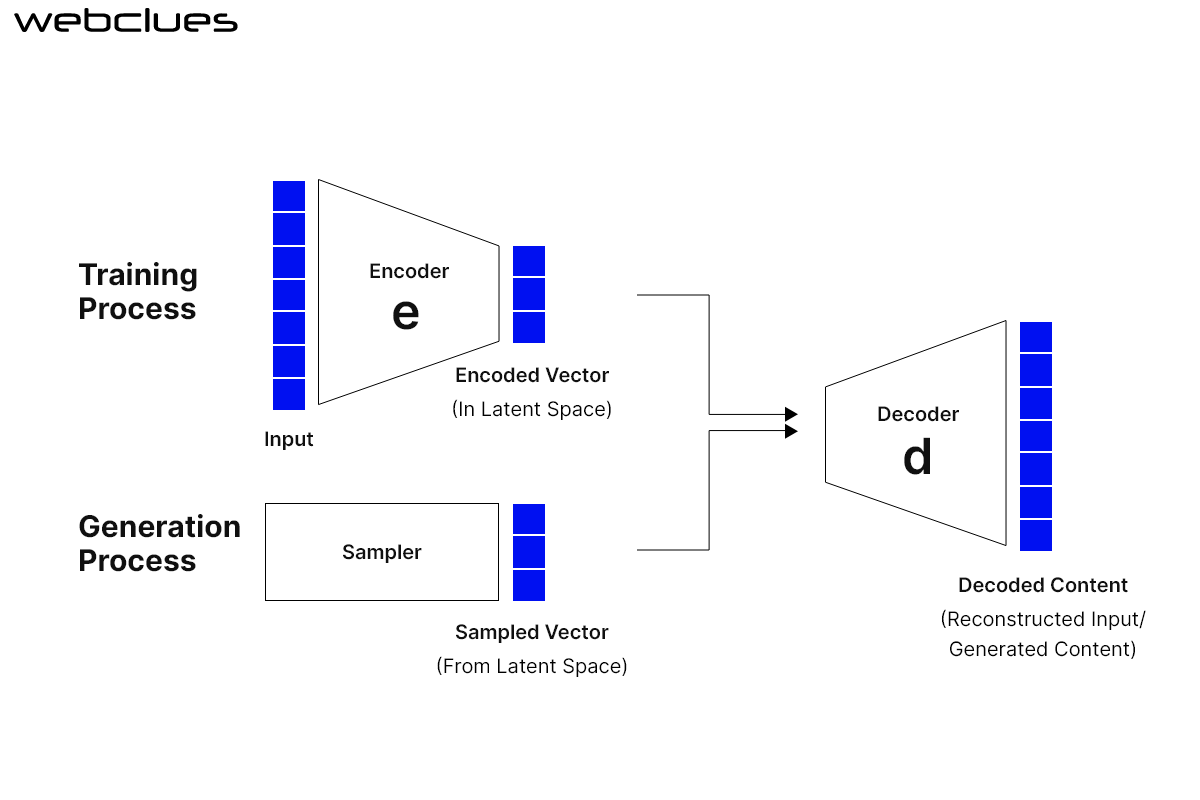
VAEs are different from traditional autoencoders in a way that they use variational inference, a statistical method to approximate complex probability distributions. It enables them to capture the uncertainty and variability in data rather than just reconstructing the input data.
Training Process of VAEs
The VAEs training process involves the following steps:
- Encoding: The encoder compresses the data into the latent space. It maps it to the parameters of a probability distribution.
- Latent Space Sampling: Random points are sampled in the latent space from the learned probability distribution based on the encoded parameters.
- Decoding: The decoder takes the latent samples and reconstructs the original input data.
- Objective Functions: They include the optimization of two objectives simultaneously during training.
- Reconstruction Loss: It measures and maximizes how well the decoder can reconstruct data given in latent representation.
- Regularization Loss: It minimizes the Kullback-Leibler (KL) divergence between the learned distribution and the actual distribution.
- Backpropagation and Optimization: Backpropagation is utilized to compute gradients to update the weights and biases of both the encoder and the decoder.
Benefits of VAEs
- Ability to generate new data samples from the learned latent space by sampling
- Learns compact and meaningful representation of the input data
- Smooth interpolation between different data points owing to the continuous nature of the latent space
Challenges of VAEs
- Achieving a balance between preserving reconstruction accuracy and getting a proper latent distribution
- Selecting an appropriate prior distribution and how it impacts the learned representations
- Addressing mode collapse, when over-regularization leads to a lack of diversity in generated samples.
Potential Applications of VAEs
- Creating diverse and realistic images
- Identifying outliers and anomalies
- Generating synthetic data for improved model performance
- Extract meaningful data representation
- Image denoising and reconstruction
- Text synthesis and language generation
- Pharmaceutical Research
Google’s DeepDream is a prominent example of a VAE. It is primarily used to generate psychedelic images. It was trained on a dataset of images edited to look psychedelic to produce similar effects.
Other Prominent Models
Alongside the above-mentioned models, there are other popular generative AI models that are pushing the boundaries of AI. Here are a few of them:
- Diffusion Models
Diffusion models work by iteratively adding noise to a base sample in the dataset and subsequently removing the noise, thus creating high-quality synthetic output. Dall-E, Stable Diffusion, Midjourney, and Google’s Imagen are popular applications based on diffusion models.
- Multimodal Models
As the name suggests, multimodal models can take input data in multiple formats, including text, audio, and images. They create sophisticated outputs by combining different modalities. Dall-E 2 and OpenAI’s GPT-4 are popular examples of multimodal models.
Wrapping It Up
Generative AI is transforming the way businesses optimize their organizational processes and approach customer engagement, content creation, and design. It helps individuals unlock their creativity and organizations deliver unique experiences to end consumers. While it is crucial to navigate the ethical considerations and biases, the potential benefits make generative AI an exciting frontier for businesses and consumers alike. Embracing this technology can be a catalyst for innovation, differentiation, and success in the digital age.
If you are curious about how generative AI can help you enhance your organizational processes and deliver optimal customer experiences, connect with our generative AI experts today!
Post Author

Nikhil Patel
Nikhil Patel, a visionary Director at WebClues Infotech, specializes in leveraging emerging tech, particularly Generative AI, to improve corporate communications. Through his insightful blog posts, he empowers businesses to succeed digitally.


Build Your Agile Team
Hire Skilled Developer From Us
Curious about which Generative AI model will be the best fit for your application?
At WebClues, our seasoned experts can provide you with valuable insights into incorporating Generative AI solutions into your business processes in the best possible manner.
Book a Free ConsultationOur Recent Blogs
Sharing knowledge helps us grow, stay motivated and stay on-track with frontier technological and design concepts. Developers and business innovators, customers and employees - our events are all about you.