
Connect with us
Corporate Video

MLOps Engineer Vs. Data Scientist: Who to Hire for Building ML Systems?
.jpg)
The software development workflow in 2026 has shifted from writing code manually to directing AI agents that build software end-to-end. Claude Code is one of the first terminal-based AI systems capable of planning, editing, testing, and validating full applications across large codebases.
This step-by-step tutorial guide explains how to use Claude Code to build production-ready AI web applications, including architecture setup, MCP integrations, prompt design, and scalable Next.js and Python implementation. It also breaks down how engineering teams reduce development time by up to 70% using agentic workflows while maintaining production-grade quality standards.
The Shift to Agentic AI-Powered Web App Development
Writing boilerplate code is no longer the best use of engineering time. Modern development workflows are shifting from autocomplete-based tools to agent-assisted systems that help plan, implement, and validate changes across multiple parts of a codebase.
For CTOs, technical founders, and product leaders, this shift changes the focus of engineering from manual implementation to architectural design, system constraints, and output validation. The value now lies in defining clear intent, structuring requirements, and reviewing AI-generated changes rather than writing every line of code manually.
In agent-driven workflows, developers provide a goal or task description. The system then interprets context from the codebase, suggests a sequence of changes, and may execute modifications within defined permissions. It can also assist in running tests or commands as part of a guided workflow, depending on the tooling configuration and safety constraints in place.
This approach can significantly reduce development time for well-scoped features, especially in repetitive engineering tasks. However, it does not remove the need for engineering discipline. Human review remains critical for ensuring correctness, security, and architectural consistency.
The developers who benefit most from this shift are those who can clearly define requirements, structure constraints effectively, and critically evaluate AI-generated outputs rather than treating them as final implementations.
If your team is looking to accelerate a product launch without sacrificing quality, partnering with a custom web development agency experienced in these new agentic workflows is the fastest path to market.
Why Claude Code is the Enterprise Standard in 2026
The market numbers clearly show where enterprise AI web app development services are heading. Claude Code reached an estimated $2.5 billion annualized run rate early this year. Engineering teams favor it because it operates entirely within the terminal, integrating seamlessly with existing developer workflows rather than forcing teams into proprietary IDEs.
Model Selection: Opus vs. Sonnet

When deploying Claude Code, development teams must choose between two primary models, depending on the task:
- Claude Opus 4.6: This is the highest-capability model for complex app development tasks. Use Opus when defining core architecture, building multi-service orchestrations, or reasoning through highly ambiguous requirements. The cost is higher, but it prevents expensive architectural mistakes.
- Claude Sonnet 4.6: This is the cost-efficient workhorse. Sonnet excels at high-volume coding, standard CRUD operations, routing logic, and UI components. It performs remarkably well on benchmark tests while costing a fraction of the Opus model.
Smart development teams use Opus for the initial architecture and design phase, then switch to Sonnet for the rapid implementation sprints.
Need expert guidance on structuring your AI-driven web application architecture? Our enterprise AI web app development services help founders turn complex requirements into scalable software.
The Power of the 1M Token Context Window
The 1-million-token context window is a core reason Claude Code outperforms earlier AI coding tools. It allows the system to load and reason across an entire application instead of working in fragmented sections.
In practical development terms, this means the agent can:
- Understand frontend, backend, and database layers simultaneously
- Execute changes across multiple files without breaking dependencies
- Maintain architectural consistency during large-scale refactors
Earlier tools with limited context windows often introduced errors because they could not “see” the full system state. The 1M context window eliminates this constraint, enabling Claude Code to operate as a full-codebase reasoning system rather than a local suggestion engine.
This directly improves reliability in complex AI web application development, especially for large SaaS products and enterprise-grade systems.
Claude Code AI Development: Setting Up Your Environment
To use Claude Code effectively, you need a properly configured local development environment. The tool operates in a terminal-based workflow and interacts with your project’s files, which makes setup relatively simple but dependent on correct system prerequisites. Claude Code typically requires Node.js 18 or higher. You can verify your installation by running:
node --version
If your version is outdated, upgrade using a Node version manager such as nvm before proceeding.
Step 1: Install the CLI Tool
Claude Code is distributed through npm as a global package (exact package name may vary depending on release version and distribution channel).
A common installation pattern is:
npm install -g <claude-code-package>
Note: Always refer to official documentation for the current package name, as CLI distribution may evolve.
Step 2: Authentication
After installation, you initialize the tool from your terminal:
claude
This typically triggers an authentication flow where you sign in through the Anthropic platform and connect your account credentials or API access.
Depending on your plan or workspace configuration, authentication may involve:
- API key setup
- account login via browser
- organization-level access controls
Step 3: Initialize Your Project
Navigate to your project directory:
cd your-saas-project
claude
At this stage, the tool can analyze your local project structure and detect key configuration files such as package.json or framework-specific setups (for example Next.js or Python environments). This helps it operate with context about your existing codebase.
Here’s a practical note for production use:
While setup is straightforward, Claude Code should be used with proper version control practices:
- Always initialize inside a Git repository
- Commit stable checkpoints before allowing large AI-driven changes
- Review diffs before applying modifications to production codebases
Building a robust SaaS MVP requires more than just installing tools. If you want to build an AI MVP for your startup quickly, hire an AI web app development company that guarantees secure, scalable deployments.
Configuring CLAUDE.md for Persistent Memory
While Claude Code automatically scans your repository, you need to provide explicit instructions regarding your architectural conventions. You do this by creating a CLAUDE.md file in the root of your project.
This file acts as the agent's persistent memory. It reads this document at the start of every session, ensuring it follows your specific coding standards without you needing to repeat them in every prompt.
A professional CLAUDE.md file should include:
- Tech Stack: Clearly list your frontend, backend, database, and styling libraries.
- Conventions: Specify rules like "Use functional React components," or "Keep business logic in the service layer, not in route handlers."
- Testing Rules: State your testing framework and coverage expectations (e.g., "All new UI components require a Jest test file").
- Key Directories: Point the AI to crucial locations, such as your database migrations folder or shared types directory.
By establishing these rules upfront, you ensure the AI generates code that seamlessly blends with your existing human-authored code.
Expanding Capabilities with MCP Integrations
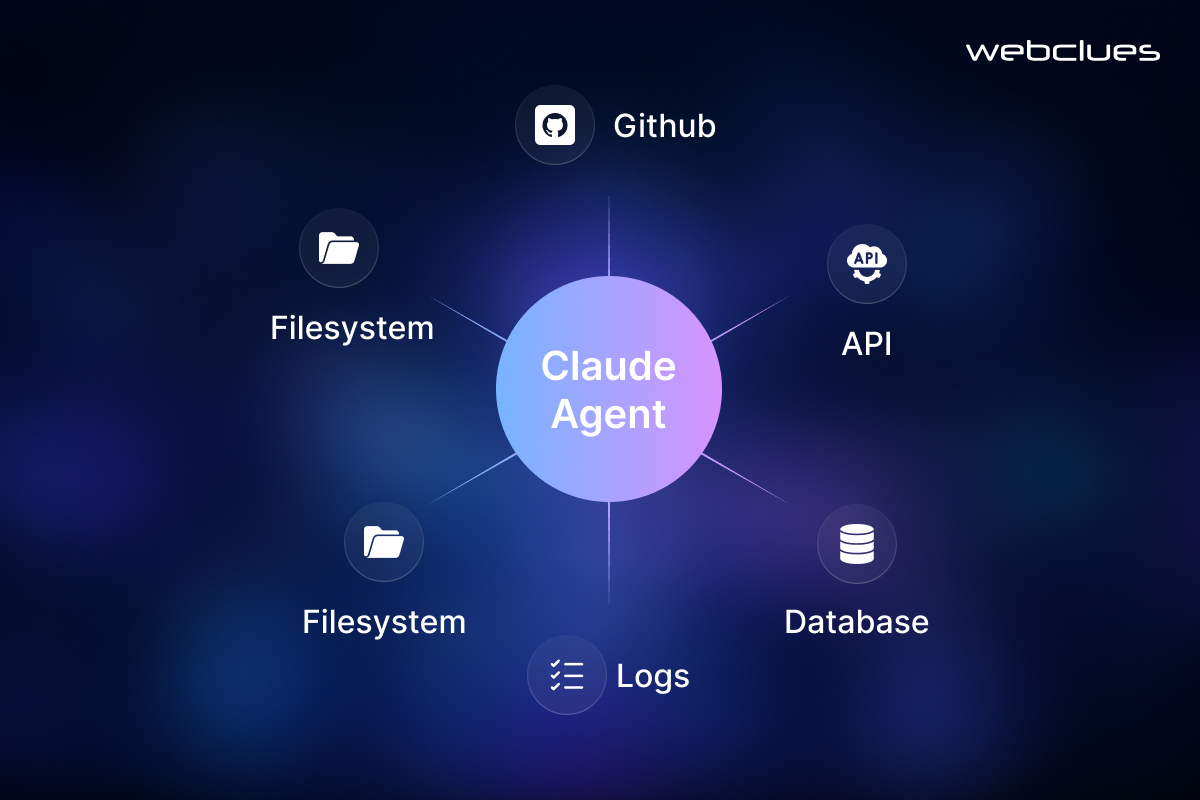
The real value of AI-powered development emerges when Claude Code is extended beyond the local codebase using the Model Context Protocol (MCP). MCP provides a standardized way for AI agents to interact with external systems such as databases, version control platforms, and testing environments.
In practice, MCP enables Claude Code to move beyond code generation and become part of a broader engineering workflow—capable of retrieving context, executing tools, and validating outputs through connected systems.
1. Database Context Integration
By connecting a PostgreSQL MCP server, the agent can read database schemas and understand table structures before generating queries or migrations. This reduces schema mismatches and improves the accuracy of generated SQL logic.
Example (conceptual setup depends on MCP implementation):
npx @modelcontextprotocol/server-postgres postgresql://localhost/mydb
With this integration, Claude Code can reason about real database structure rather than assuming schema details, which improves reliability in backend development workflows.
2. GitHub Workflow Integration
GitHub MCP integration allows the agent to interact with repository context such as issues, pull requests, and file history. This enables workflows where the AI can:
- Read issue descriptions
- Suggest or generate fixes
- Create branch-ready code changes
However, final actions such as merging pull requests still require human review and approval in standard production pipelines.
npx @modelcontextprotocol/server-github
This makes the development cycle more interactive, where Claude assists in implementation rather than independently managing the full lifecycle.
3. Automated Browser Testing
A headless browser MCP server (such as Puppeteer-based setups) allows Claude Code to validate UI behavior after code changes. It can simulate user interactions, verify page rendering, and detect runtime issues in frontend flows.
npx @modelcontextprotocol/server-puppeteer
This is particularly useful for regression testing and validating UI changes during iterative development cycles.
When database context, version control awareness, and browser testing are combined through MCP, development workflows become significantly more integrated. The agent can:
- Understand backend schema context
- Generate or modify application logic
- Validate UI behavior through automated testing tools
- Propose changes for human-reviewed commits
It creates a semi-automated development loop, where AI reduces implementation overhead while engineers maintain architectural control, security oversight, and deployment responsibility.
This is how top-tier web development companies accelerate delivery timelines and reduce overall software development costs.
The Mechanics of Autonomous File Editing
Autonomous file editing represents the core difference between legacy AI coding assistants and modern terminal-based agents. When you initiate a command in Claude Code, it does not simply output text for you to copy and paste. Instead, it reads the relevant files, formulates an execution plan, modifies the filesystem directly, runs necessary validation commands, and presents a comprehensive summary of the changes.
Understanding this execution pattern is critical for effective AI-powered web app development. A typical feature implementation follows a distinct sequence. First, the agent breaks your instruction into manageable subtasks. It then scans existing files to grasp the current architectural state, planning modifications across all affected areas. Next, it executes the edits sequentially—updating imports, configuring routes, and adding functions. Finally, it runs your test suite to ensure no existing functionality is broken.
This autonomous execution grants development teams immense speed, but it requires disciplined oversight. You must review the agent's work before committing it to your repository. Never run Claude Code in a directory with uncommitted changes that you are not prepared to lose. Always start from a clean Git state. This ensures that every modification is clearly visible as a diff, allowing you to accept or revert changes safely.
Prompting Strategies for Terminal Agents (With Examples)
The quality of output you receive from this Claude Code AI development depends heavily on the specificity of your instructions. Vague prompts lead to incomplete implementations, while precise prompts yield production-ready code.
A highly effective prompt structure for terminal agents includes an action verb, the specific component or file, the exact behavior expected, relevant constraints, and clear success criteria.
Weak Prompt Example:
"Add authentication to the web application."
Strong Prompt Example:
"Add email and password authentication to this Next.js application using Supabase Auth. Create a /login page with a form component, a /register page with an email confirmation flow, and a middleware file that protects all routes under /dashboard. Use the existing Supabase client in /lib/supabase.ts. Write tests for the authentication flow using the existing Jest setup. The login should redirect to /dashboard on success."
To avoid getting stuck in AI loops where the model repeatedly fails to resolve an error, use structural commands. Instruct the agent to "Stop and summarize what you have tried so far before attempting another approach." For complex architectural shifts, tell the agent to "Do not modify any files until you have shown me your implementation plan." Breaking large tasks into sequential instructions rather than issuing one compound prompt will drastically improve the reliability of your AI web application architecture.
Practical Framework for Building AI-Powered Web Apps with Claude Code
Integrating Claude Code into your daily workflow requires framework-specific strategies. Here is how to apply agentic development across the most popular modern stacks.
Building a React App with Claude Code
Building a scalable React application with the help of a React native app development services provider relies on a four-phase pattern: scaffold, feature, test, and refine.
Begin by scaffolding the project foundation. Ask Claude Code to set up the folder structure using feature-based organization, configure routing with React Router, and initialize state management libraries. Do not ask for feature components during this initial step; focus entirely on the structural foundation.
Once the foundation is verified, move to feature implementation. Instruct the agent to build specific components, like a data grid or a user dashboard, following the existing patterns in your repository.
After the feature is built, direct the agent to write tests using React Testing Library to cover loading states, empty states, and populated data views. Finally, enter the refinement phase by asking the agent to review TypeScript types, correct accessibility ARIA labels, and ensure error handling is user-visible.
Advanced Next.js Development
Next.js development benefits significantly from Claude Code's deep understanding of the App Router paradigm and Server Components. For teams working with modern Next.js development services, this combination becomes especially powerful because it aligns directly with scalable production architecture patterns used in enterprise-grade applications.
When setting up your persistent memory file, explicitly define your Next.js conventions. State that Server Components are the default and Client Components should only be used when interactivity is required.
When prompting for Next.js features, be specific about the data layer. Direct the agent to create Server Components that fetch data directly from your database via Prisma, bypassing traditional API routes where appropriate. If a component throws a hydration error due to mixed server and client logic, instruct Claude Code to identify the interactive elements, extract them into a separate Client Component, and keep the data fetching secure on the server side.
Best Practices for Python Apps
Python development introduces different environmental constraints, specifically regarding virtual environments and synchronous versus asynchronous execution. Whether you are building a FastAPI backend or a data pipeline, your initial setup must clearly define dependency management rules.
Direct Claude Code to build RESTful endpoints using specific schemas for data validation. For example, instruct the agent to create Pydantic models for user creation and updates, build SQLAlchemy models for database interaction, and keep the route handlers thin by delegating business logic to a dedicated service layer.
If version conflicts arise in your requirements.txt, ask the agent to identify the conflict and update the import statements across your codebase without automatically running install commands.
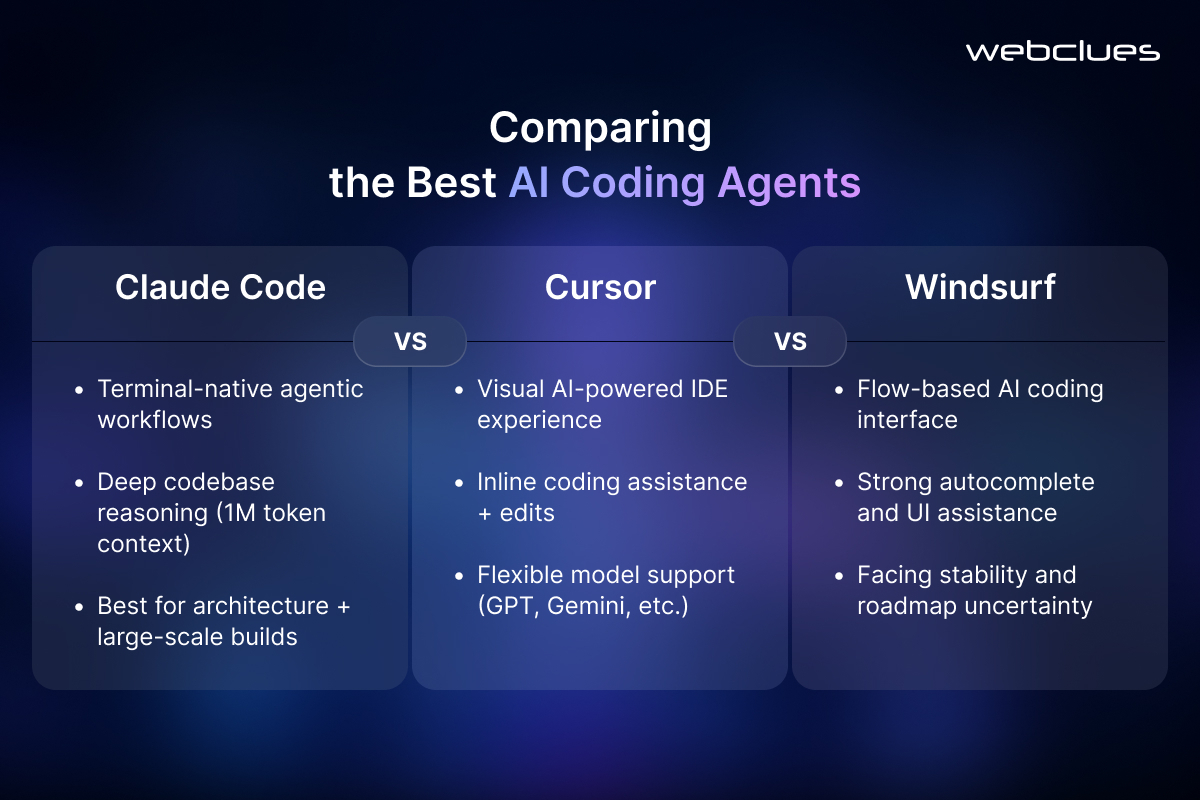
Comparing the Best AI Coding Agents: Claude Code vs. Cursor vs. Windsurf
Decision-makers evaluating tools for enterprise AI web app development services must choose the right assistant for their specific organizational needs. The landscape is dominated by three main contenders.
Claude Code vs. Cursor 2026
Claude Code and Cursor serve entirely different workflow preferences. Claude Code operates natively in the terminal and excels at autonomous, multi-file agentic workflows. It leverages a massive 1-million-token context window to read entire codebases simultaneously, making it ideal for complex architectural refactors and large-scale application builds.
Cursor functions as an AI-native IDE built on a visual interface. It is the premier choice for developers who prefer visual code editing with inline AI assistance. Cursor supports multiple models, including GPT-4 and Gemini, offering flexibility for teams that want to switch between AI providers.
Choose Claude Code when your team runs autonomous multi-step workflows and requires deep architectural reasoning. Choose Cursor when your team prioritizes visual diffs and incremental feature development.
Head-to-Head Comparision: Claude Code vs. Windsurf
Windsurf previously offered strong flow-based autocomplete and visual AI assistance. However, recent market acquisitions have shifted its trajectory, introducing product stability concerns.
Claude Code remains a primary, heavily supported product driving massive enterprise adoption. Its native MCP support and terminal-first architecture provide a stable, predictable foundation for teams making tooling decisions intended to last multiple years. For long-term enterprise projects, stability and consistent updates make Claude Code the safer, more robust choice for custom AI application development services.
Accelerate AI Web App Development with WebClues Using Claude Code!
Mastering terminal agents is only one part of the equation. Building production-grade software that scales securely requires deep engineering expertise. While AI tools drastically reduce the time needed to write standard features, they can introduce subtle architectural flaws or technical debt if not rigorously reviewed.
For founders and technical leaders looking to launch robust SaaS products without the overhead of a massive internal team, partnering with experts is the most strategic move. Professional teams combine the velocity of agentic AI coding with the rigor of senior engineering oversight. From configuring complex MCP servers to auditing AI-generated codebases for security and performance, expert developers ensure your application is truly production-ready.
Contact us and secure your competitive advantage today. Partner with WebClues Infotech, a top-tier web development company, to deliver scalable, AI-powered web applications that drive real business outcomes.
Post Author

Nikhil Patel
Nikhil Patel, a visionary Director at WebClues Infotech, specializes in leveraging emerging tech, particularly Generative AI, to improve corporate communications. Through his insightful blog posts, he empowers businesses to succeed digitally.


Build Your Agile Team
Hire Skilled Developer From Us
Build Production-Ready AI/ML Systems With the Right Team
Most AI/ML initiatives fail not because of poor models, but because they never reach production in a stable, scalable way. If you're unsure whether you need a Data Scientist to build models or an MLOps Engineer to operationalize them, the gap between experimentation and production is where most projects break. We help companies design the right AI team structure, deploy machine learning systems properly, and ensure models deliver consistent business impact at scale. Talk to us to move from experimentation to real-world execution without delays or rework.
Connect Now!Frequently Asked Questions
Our Recent Blogs
Sharing knowledge helps us grow, stay motivated and stay on-track with frontier technological and design concepts. Developers and business innovators, customers and employees - our events are all about you.